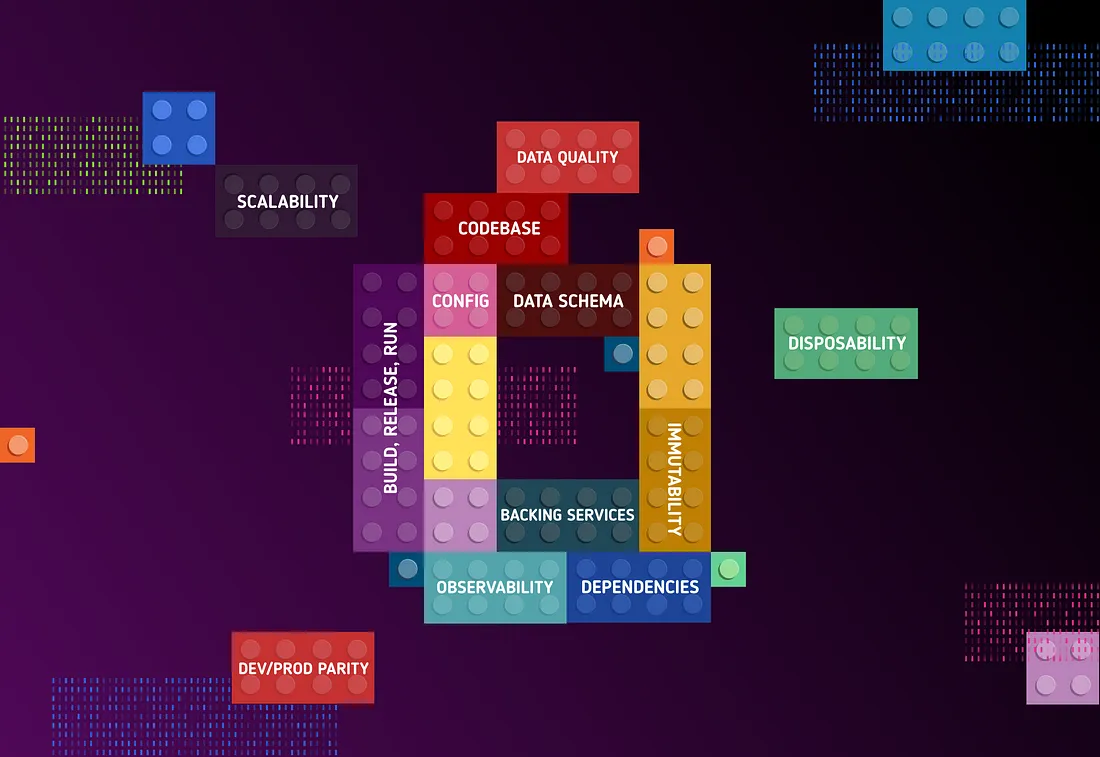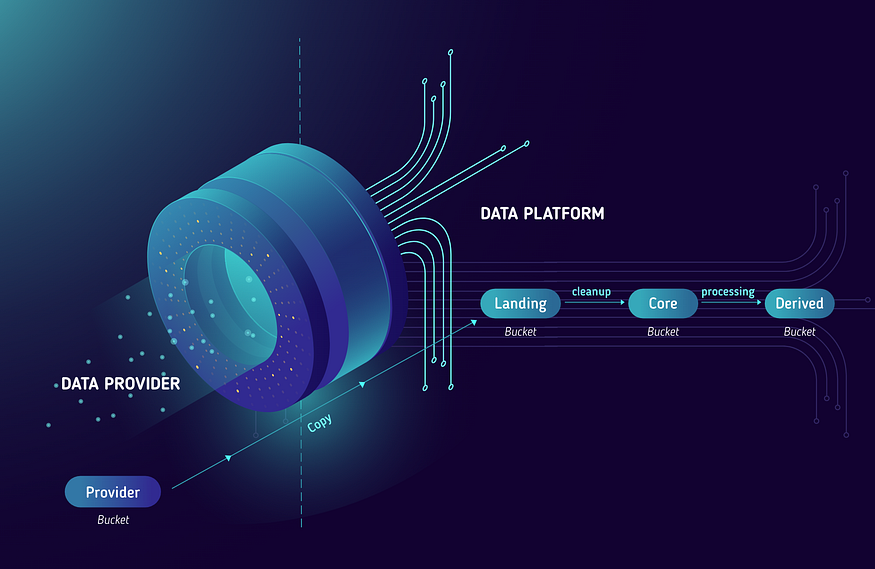
Data storage patterns, versioning and partitions
When you have large volumes of data, storing it logically helps users discover information and makes understanding the information easier. In this post, we talk about some of the techniques we use to do so in our application.In this post, we are going to use the terminology of AWS S3 buckets to store information. The same techniques can be applied on other cloud, non cloud providers and bare metal servers. Most setups will include a high bandwidth low latency network...
Read